超时大时延问题自助分析
1.Tcaplus API日志分析
Tcaplus api log日志文件和Perf日志在同一个目录下
log日志文件配置
1.1 Api Error日志
请业务侧注意game server请求到Tcaplus DB和Tcaplus DB回包到game server的异常,这两个阶段产生的异常导致的超时,需要业务侧监控
情况1: Api请求异常,访问请求未到达Tcaplus DB,发送失败,api接口会返回错误,打印error日志
情况2:
业务侧收包不及时,查看Tcaplus api log日志文件,看有没有 no call TcaplusServer.RecvResponse的日志
这种一般是包已经到了sdk侧,业务没有及时调用TcaplusServer.RecvResponse去收包导致的大时延
大概率是业务性能吃满,导致的卡顿,或者gdb卡顿,或者机器卡顿,业务可咨询腾讯云,或者自行定位

1.2 Perf日志
1.2.1 API每分钟会统计性能信息,并打印到 perf 类似命名的log中
注意3.46.0.199774.x86 64 release 20220530及以后的版本支持pref日志采集,如果sdk低于此版本,建议升级
1 代码解释代码改写#查找log :
2 find ./ *perf*.log*
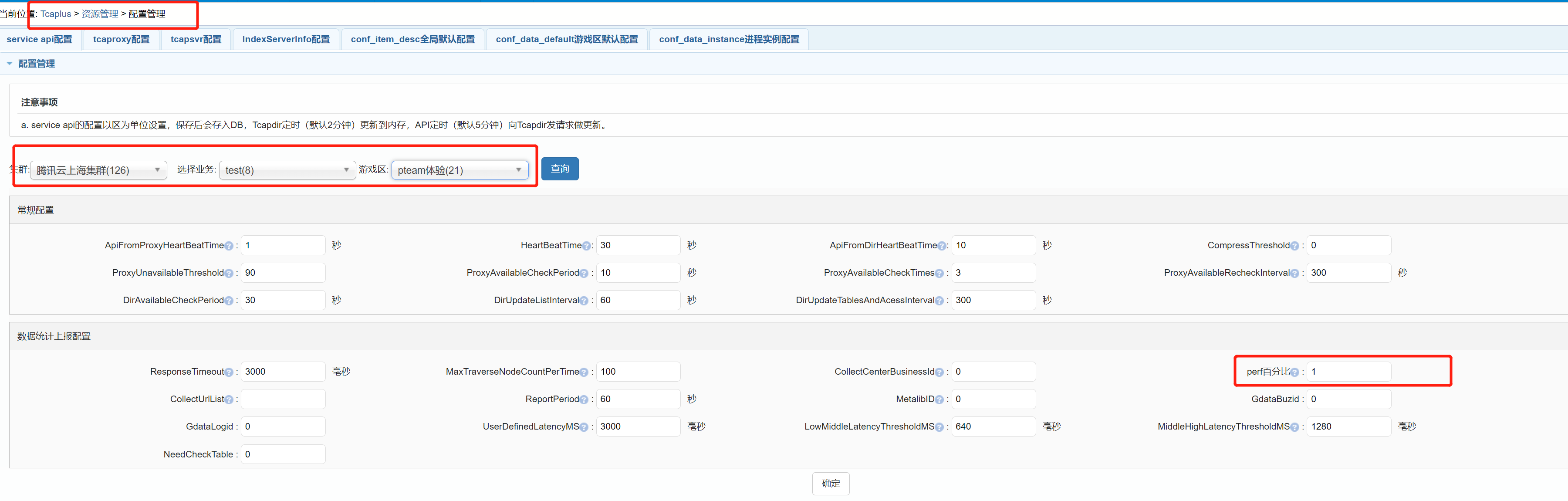
1.2.2 如果没有Perf日志,请联系dba在oms上打开Perf,Perf百分比调到100
注意,修改Pref百分比配置大概5-7分钟生效,排查超时问题完成后pref百分比请改回默认值1
1.2.3 会按区打印汇总信息(每分钟一次)
1 ZoneStatistic:
2 [ReqSucNum]:请求成功数
3 [ReqErrNum]:请求失败数
4 [RespSucNum]: 响应成功数
5 [RespWarnNum]:响应Warnning数,一般是业务逻辑错误,像记录不存在,字段不存在
6 [RespErrNum]:响应失败数,一般是后端错误,查看Error日志
7 [SimpleReadResCount]:简单读响应数
8 [SimpleReadTimeoutNum]:简单读超时数
9 [SimpleReadAverageLatency(ms)]:简单读平均时延
10 [SimpleReadMaxLatency(ms)]: 简单读最大时延(最大时延proxyip 最大时延的命令字 最大时延时间点)
11 [SimpleWriteResCount]:简单写响应数
12 [SimpleWriteTimeoutNum]:简单写超时数
13 [SimpleWriteAverageLatency(ms)]:简单写平均时延
14 [SimpleWriteMaxLatency(ms)]:简单写最大时延(最大时延proxyip 最大时延的命令字 最大时延时间点)
15 [ComplexReadResCount]:复杂读响应数
16 [ComplexReadTimeoutNum]:复杂读超时数
17 [ComplexReadAverageLatency(ms)]:复杂读平均时延
18 [ComplexReadMaxLatency(ms)]:复杂读最大时延(最大时延proxyip 最大时延的命令字 最大时延时间点)
19 [ComplexWriteResCount]:复杂写响应数
20 [ComplexWriteTimeoutNum]:复杂写超时数
21 [ComplexWriteAverageLatency(ms)]:复杂写平均时延
22 [ComplexWriteMaxLatency(ms)]:复杂写最大时延(最大时延proxyip 最大时延的命令字 最大时延时间点)
23 [ApiFindRouteErr]:路由错误次数,api发送请求时,找不到可用的proxy
24 [ApiSendBuffFull]:网络发送buffer满错误次数
25
26 ZonePerf:
27 [PerfRspCount(100%)]:携带perf信息的响应数,100%表示oms页面上开启的perf请求的百分比,(100%每个请求和响应都携带perf信息,由于perf会有一定的性能损耗(很小),所以oms上可以配置百分比)
28 [ApiTotal ] api总的时延区间,10ms一下的数量,100ms以下的数量,500ms以下的数量,1000ms以下的数量,1000ms以上的数量,最大时延
29 [ApiToProxy ] api到proxy的时延区间
30 [ProxyReqHandle] proxy处理请求的时延区间
31 [ProxyToSvr ] proxy到svr的时延区间
32 [SvrHandle ] svr处理的时延区间
33 [SvrToProxy ] svr到proxy的时延区间
34 [ProxyRspHandle] proxy处理响应的时延区间
35 [ProxyToApi ] proxy到api的时延区间

1.2.4 会打印该区的最大时延top3的(不超过1s)proxy的perf信息

1.2.5 会打印该区的最大时延超过1s的proxy的perf信息
 根据pref日志打印的大时延日志对应的ip在tmp(网管系统 - 首页)上查询对应时间点是否网络或者机器异常
根据pref日志打印的大时延日志对应的ip在tmp(网管系统 - 首页)上查询对应时间点是否网络或者机器异常
1.2.6 Go Api日志类似(v0.6.23及其以上版本)
需要开启INFO日志,并且OMS上打开开关,perf统计信息会打印在主日志中

1.2.7 分析实践
ApiToProxy 和 ProxyToApi 时延高,这种一般是api和proxy间的网络抖动导致,网络传输时延高,可查看tmp上的tcp重传率 ProxyToSvr 和 SvrToProxy 时延高,这种一般是proxy和svr间的网络抖动导致,网络传输时延高,可查看tmp上的tcp重传率 ProxyReqHandle 和 ProxyRspHandle 时延高,一般是proxy性能不足,可联系help定位,扩容proxy SvrHandle 时延高,一般是svr性能不足,可联系help定位,扩容svr
1.2.8 注意
所有perf信息都是简单请求的perf信息。</br>复杂请求(一应多答,listgetall,getbypartkey等等)本身比较耗时,统计复杂,参考意义不大,不会统计perf</br>ntp时间不同步可能导致perf统计不准确,ApiTotal的时间取自本地,该区间的统计是准确的
2. oms控制台查看proxy有没有大时延
自建集群环境、国内idc、dev环境,项目组用户在oms控制台查看监控视图。 腾讯云环境内部用户,请联系dba或者Tcaplus_Helper号开通相关oms控制台权限查看(腾讯云环境外部用户,请联系Tcaplus 团队查看)
旧oms:

新oms:

3. 联系Tcaplus_Helper人工服务号,dir上查看timeout
如果不方便看日志,perf也没开,proxy也没有大时延 此时 大概率是客户端卡顿,或者网络抖动
客户端卡顿:
查找每个dir的error日志,看有没有类似的日志 timeout request too high

网络抖动或者proxy丢包:
看下客户端日志(搜索TraverseForeleteTimeutNode),有没有打印是哪个proxy超时,登录proxy,查看proxy是否有错误信息,查看gamesvr和proxy的tcp重传率,让腾讯云协助定位
