TcaplusDB是什么?
TcaplusDB 是腾讯出品的分布式NoSQL数据库,存储和调度的代码完全自研。具备缓存+落地融合架构、PB级存储、毫秒级时延、无损水平扩展和复杂数据结构等特性。客户覆盖游戏、互联网、政务、金融、制造和物联网等领域。
高性能。内存和硬盘热冷数据 LRU 交换、数据落地 SSD 盘、数据多机分布等保障性能最大化,单机 QPS 达 10 万/秒,时延小于 10 毫秒。
高可用。双机热备容灾机制,保证系统故障时的快速恢复。硬件或操作系统故障快速恢复,可用率达 99.999% 。
低成本。提供进程内数据在内存和磁盘的切换能力,活跃数据存内存,非活跃数据存磁盘。比全内存型存储节省约 70% 成本,比 Redis + MySQL 节省约 40% 。
动态扩展。存储空间无上限,容量可以根据游戏的实际需要进行动态的扩展和收缩,且不影响游戏运营,轻松应对业务规模急剧变化。
易于使用。支持 API 接口调用,常用操作(如加表、改表、删表、数据清理等)WEB 化,扩容、缩容、备份等运维操作系统自动化。
1. TcaplusDB的概念与其它数据库(MySQL、MongoDB)的概念映射关系
| MySQL术语/概念 | MongoDB术语/概念 | TcaplusDB术语/概念 | 解释/说明 |
|---|---|---|---|
| database | database | zone(table group) | 数据库/表格组 |
| table | collection | table | 数据表/集合 |
| row | document | record | 数据记录/行/文档 |
| column | field | field | 数据字段/列/域 |
| index | index | index | 索引 |
| primary key | primary key | primary key | "主键,MongoDB自动将_id字段设置为主键" |
2. TcaplusDB的主要概念
TcaplusDB的数据模型包含业务(App)、游戏区(Zone,表格组)、表(Table)、索引(Index)等主要概念,这些概念的关系可以下图表示。
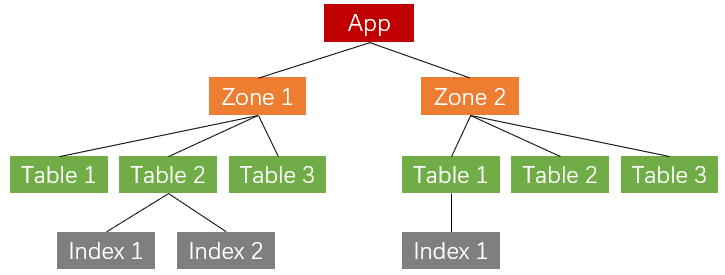
一个业务包含多个游戏区,一个游戏区可以创建多张表,又可以为每张表定义多个本地索引和创建分布式索引。
2.1. 业务(App)
业务是TcaplusDB对数据库使用方的定义,通常是一个项目组或公司,比如“王者荣耀”业务,业务是逻辑上的概念,创建业务并不涉及到资源的分配。
一个业务下可以跨集群创建多个游戏区(Zone,表格组),但一个游戏区只能使用一个集群的资源。
创建业务的方法参见创建业务文档。
2.2. 游戏区(Zone,表格组)
游戏区(Zone,表格组)与传统数据库的Database的概念相似,也可以理解为是一个表格的集群。一个游戏区下可以创建多张表,同一个游戏区下,表格不能重名。
业务可以结合自身的实际情况,对游戏区进行规划。可以按用途不同,创建“测试”游戏区和“正式”游戏区,也可以按用户平台的不同,创建“微信区”和“QQ区”,等等。
创建游戏区的方法参见创建游戏区文档。
2.3. 表(Table)
TcaplusDB中的表与传统数据库的中的表的概念相似,可以理解为具有相同Schema的数据集合。
TcaplusDB中每张表至少有一个数据分片(占用一个Shard资源),随着数据量的增长或减少,可以增加或者减少表格的数据分片。目前数据分片的扩容操作是由系统DBA负责执行,用户创建表后,如果预估表格数据和访问量在短时间可能会迅速增长,则需要提前联系系统DBA进行扩容。
TcaplusDB表由主键字段和非主键字段两部分组成,主键字段最多可以指定8个,普通字段(非主键字段)最多可以指定256个。
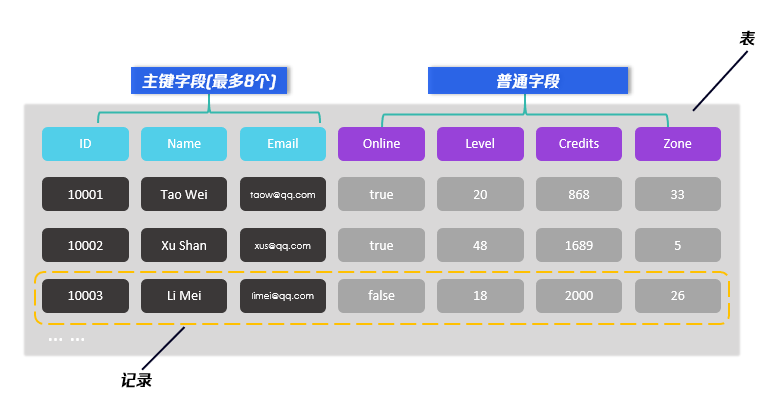
TcaplusDB中的表按照表定义和访问的方式可分为PB表(Protobuf表)和TDR表
PB表使用PB文件定义表结构,并且通过PB SDK进行访问。TDR表使用TDR文件定义表结构,并且通过TDR SDK进行访问。TDR是与PB类似的一种序列化反序列化协议。PB表与TDR表并无本质区别,用户可以根据自己对PB或TDR的熟悉程度,来决定使用PB表还是TDR表。需要注意的是当前TcaplusDB的PB表和TDR表支持的功能范围有些差异,用户在选择使用何种表类型的时候,也需要考虑功能是否能满足业务需求。
TDR表和PB表的主要功能差异点,见下表:
| 功能 | TDR表 | PB表 |
|---|---|---|
| Schema Free | 不支持 | 支持 |
| RESTFul API | 不支持 | 支持 |
| MySQL协议兼容 | 支持 | 不支持 |
| Java SDK | 支持 | 不支持 |
| TopN索引 | 支持 | 不支持 |
TcaplusDB中的表按照表记录类型又可以分为Generic表和List表
Generic表中每个Key对应一条数据,数据的Key不能重复。List表中Key相同的多条数据以一个列表的形式存储在数据表中。
创建表的方法参见创建表文档。
2.4. 主键(Primary Key)
TcaplusDB的表定义要求设置主键,主键是数据记录的唯一标识,用于唯一定位一条数据。
2.5. 分表因子(Splittable Key)
TcaplusDB的表定义要求设置一个分表因子(splittablekey)属性,分表因子必须是主键字段(primarykey)的子集,分表因子可以是一个字段,也可以是多个字段的组合。
本质上,splittable key所包含的字段将参与hash计算,然后根据hash值决定该记录被存储至集群中的哪个节点。因此,一个表的多个记录,它们splittable key字段的值应该是多样化的,这样数据分布才比较均衡。
举例来说,假设一个表的primary key是"uid,role_id,zone_id",其中uid和role_id的值足够多样,而zone_id只有几个、最多几百个不同的值,那么使用zone_id作为splittable key将会有很大的风险,若某个特定zone_id对应的记录特别多,会导致Tcaplus特定的存储节点严重过载,甚至数据量超过机器存储容量而无法提供服务。假设一个表的分表因子是性别,这会导致数据最多分布到2个存储节点, 那么业务的分布式能力就会被限制到最多2个存储节点的性能上。
分表因子决定了数据的物理分布(系统根据该字段做hash分散到不同节点),建议取离散度高的字段,利于负载均衡。不指定时默认取primary key的所有字段。
2.6. 记录(Record)
TcaplusDB记录由一行字符串组成每个字段的数字都支持嵌套类型,嵌套最多32层。单个记录大小最高10MB,可以将常用的对象文件序列化成二进制文件存储。

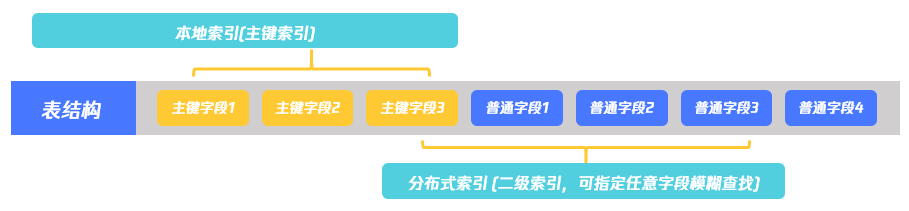
2.7. 索引(Index)
本地索引:基于TcaplusDB主键字段建立的索引,在建表时随表一起建立。
全局索引:基于TcaplusDB表一级字段(包括主键字段和非主键字段)建立的索引。
通过本地索引和全局索引,用户可方便利用索引进行数据查询。优势:
基于本地索引查询,可以满足用户通过部分主键字段进行索引查询
基于全局索引,可以满足用户通过任意一级字段进行多种形式查询,如范围、模糊、聚合、分页等。
3. TcaplusDB典型应用场景
参见典型应用场景介绍;
4. TcaplusDB环境准备
TcaplusDB目前提供了云服务、本地集群部署和本地Docker容器部署三种部署方式,详见TcaplusDB环境准备。