TcaplusDB OMS Console - Set Write Buffer
1. Function Descriptions
It is used to synchronize the data in TcaplusDB to external systems (such as MySQL, Kafka, etc.).
2. Steps
App Management - Table Management - Select the table needs write buffer configuration - Edit.
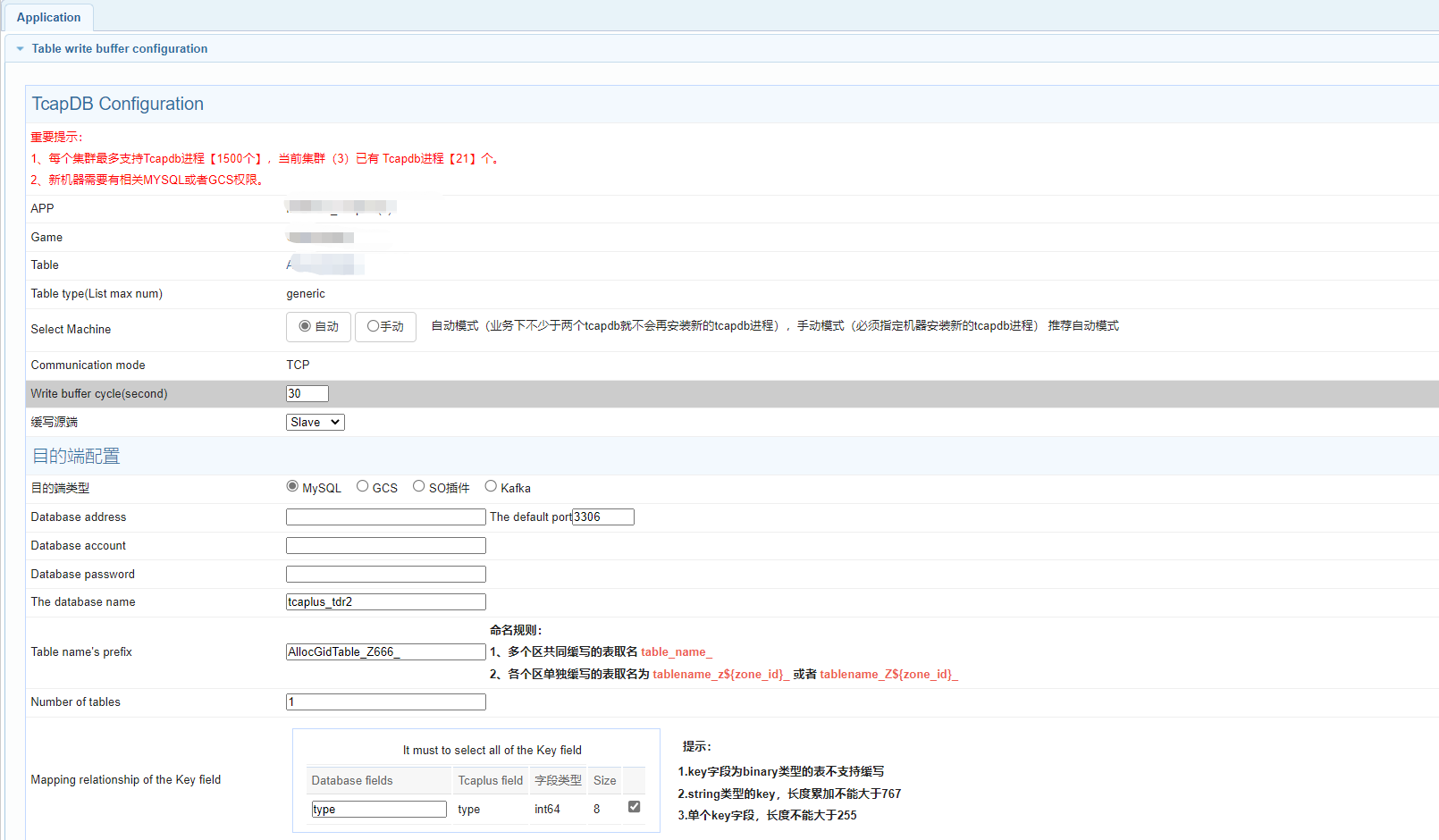
Fill in the write buffer configuration and destination configuration.
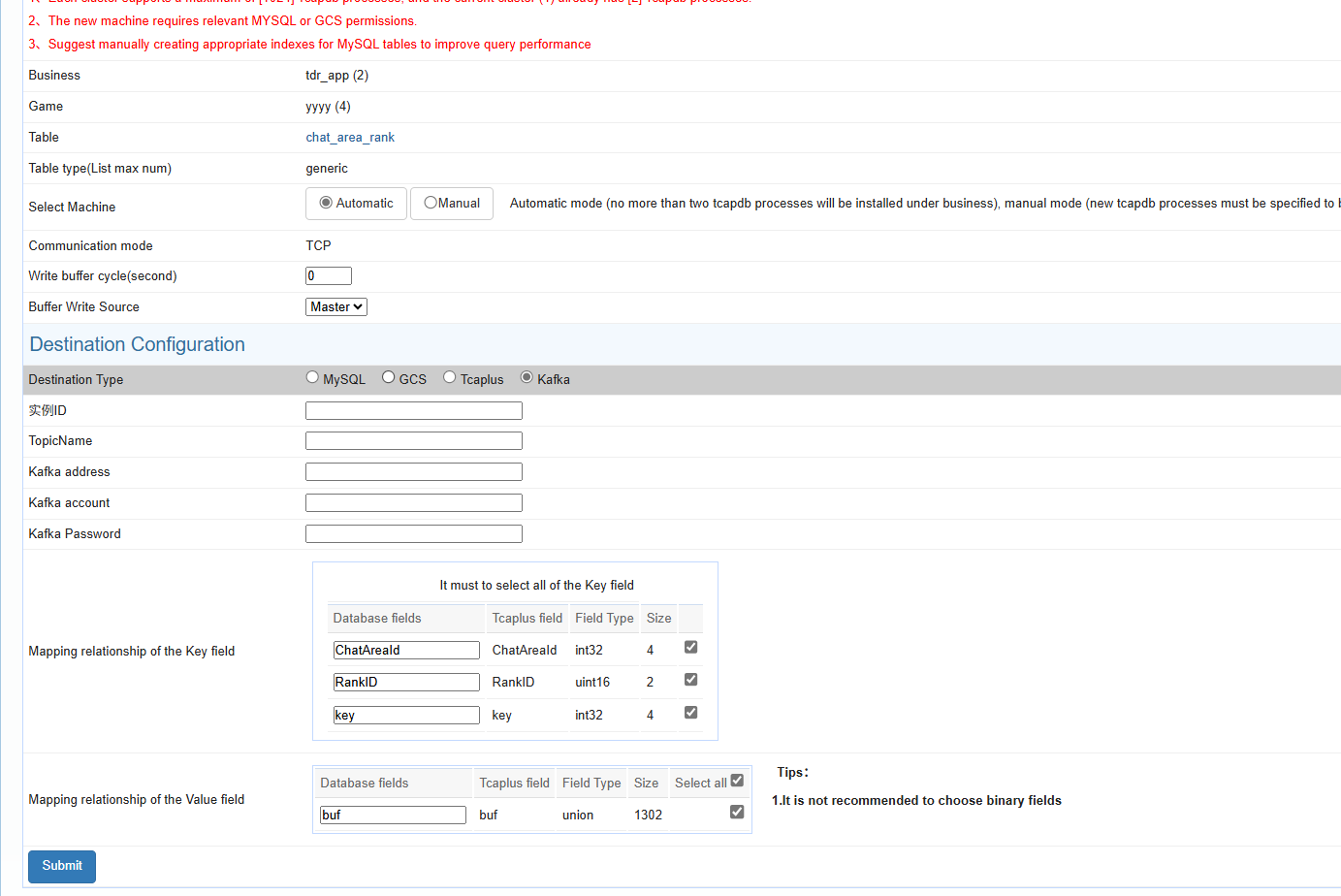
After all the information on the page is filled in as required, click the Submit button and it will jump to the transaction page. On the transaction page, you can check whether the write buffer configuration is successful.
- If the transaction page displays a "Completed" status, it indicates that the write buffer configuration has succeeded.
- If the transaction page displays a "Suspended" or "Abort" status, it indicates that the write buffer configuration has failed. It needs to manually find the cause of the failure and reconfigure;
2.1. Write Buffer Configuration Descriptions
- Machine selection: Automatic mode (no less than two tcapdbs in the service will not install new tcapdb processes), manual mode (the machine must be specified to install new tcapdb processes). It is the recommended automatic mode.
- Write buffer circle: Time period for synchronizing a record from tcapsvr to tcapdb;
- Application object: Please select Slave;
2.2. Write Buffer Destination Type
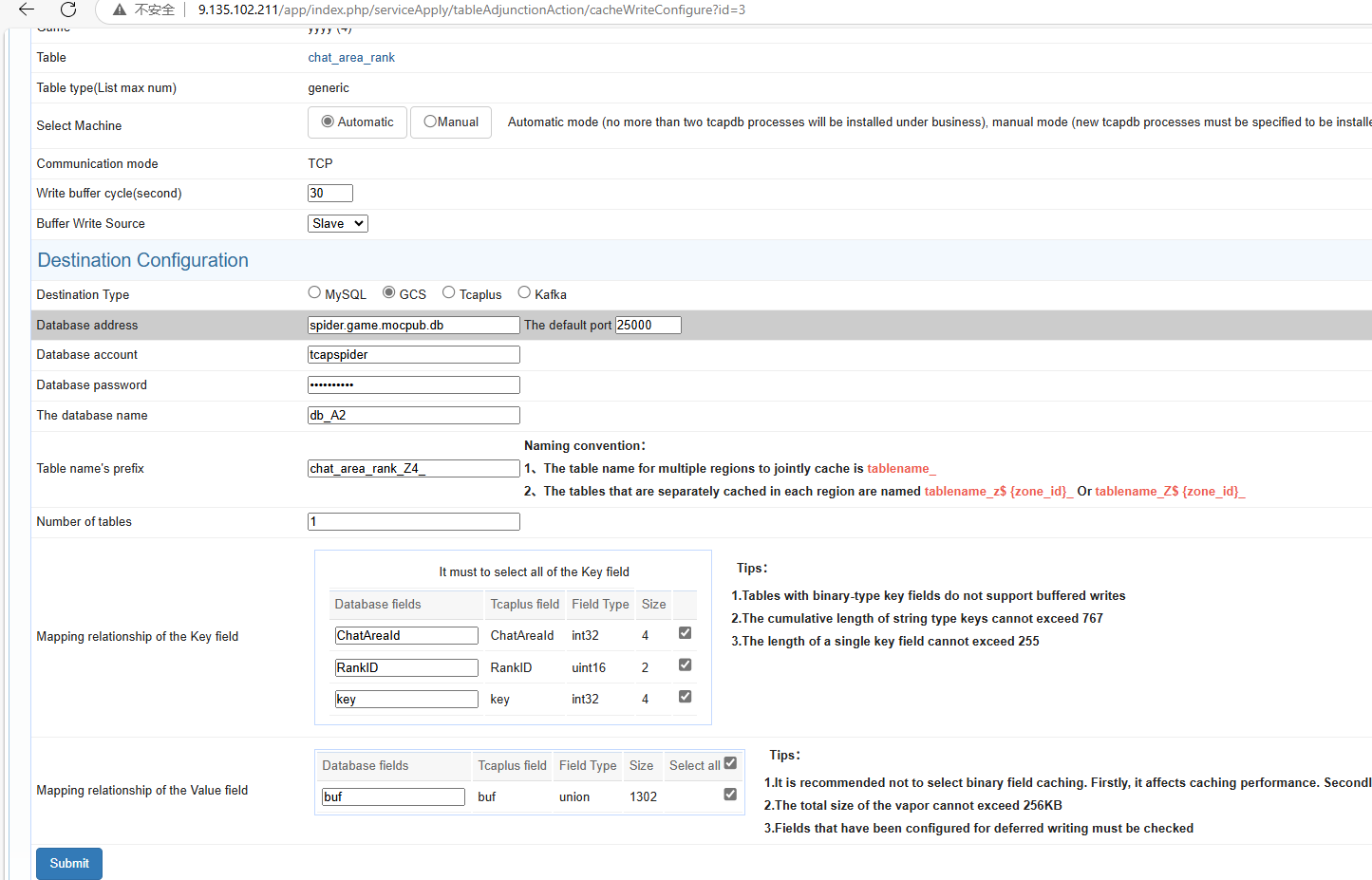
- Mysql: The source data is written to the mysql database. The number of splittables and the mapping relationship of fields can be configured.
- Database address: Fill in the IP address and port number of the machine where the database is located;
- Database account: Fill in the account for creating the database;
- Database password: Fill in the database password;
- Database name: Fill in the database name;
- Table name prefix: Fill in the prefix of the table created in the database;
- Number of splittables: Fill in the number of splittables created in the database,By default, there is one sub table, and after configuring buffering, the table name in MySQL will be marked with 0. If there are multiple sub tables, it will be 0 1* N;
- Key field mapping: For database fields, please fill in the key field names of the tables created in the database (which must be the same as the field names defined in xml). At present, all key fields must be selected;
Value field mapping: For database fields, please fill in the names of each Value field of the tables created in the database (which must be the same as the field names defined in xml), and check the field names to be imported;
GCS: Similar to Mysql, the number of splittables and the mapping relationship of fields can be configured.
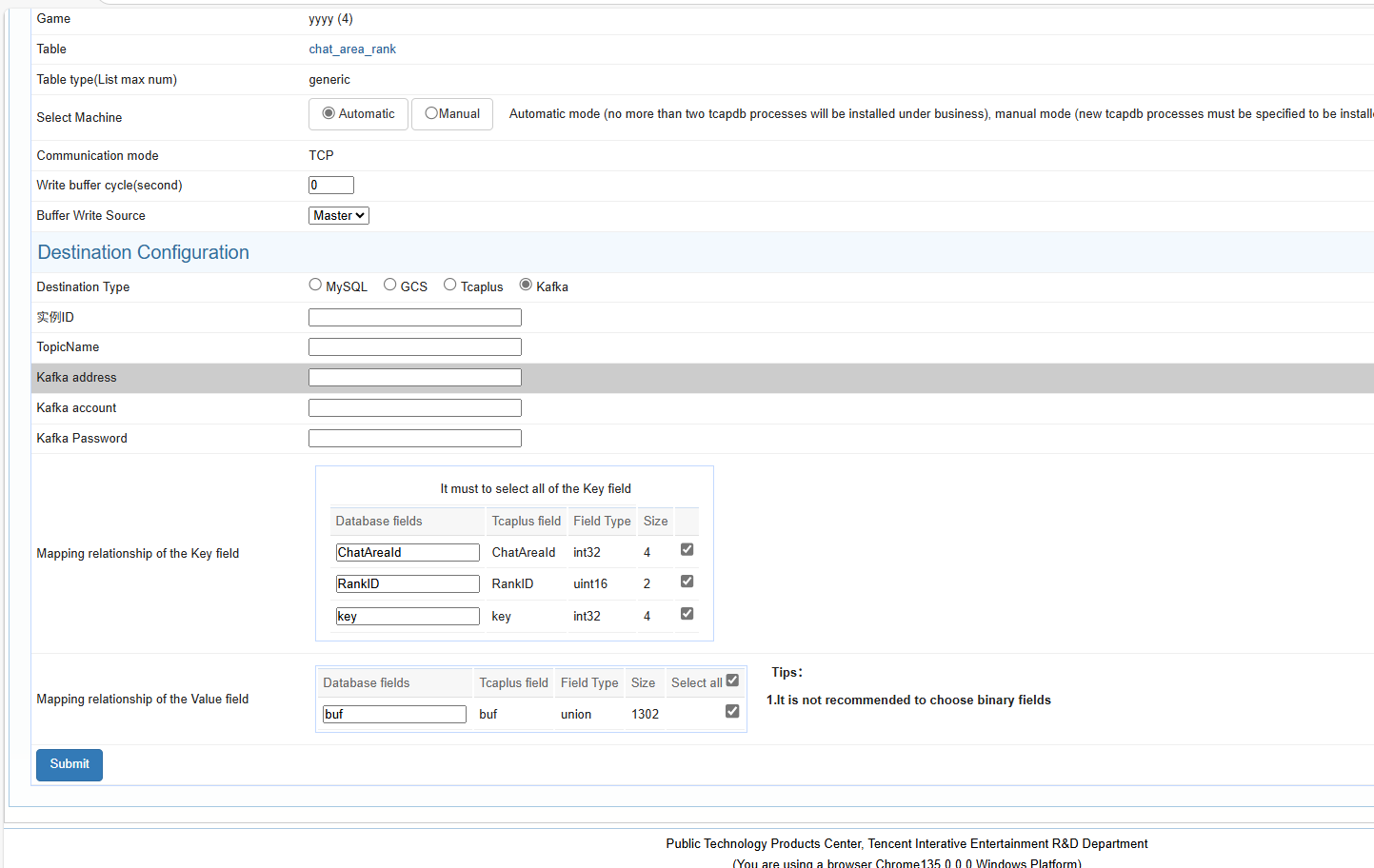
- Kafka: data is buffered into the kafka queue.
3. Notations
- Apps require to be on the tcapdb before the buffer can be configured.
- Tables with distributed indexes must delete the indexes before the buffer can be configured.
- At present, a tcapdb can only support one tcaplus table.
- Tables that have been configured for buffering will not be affected by subsequent table changes. For the newly added value fields for subsequent table changes, if buffering requires adding new fields, please contact the DBA to reconfigure buffering
4. Introduction to Buffer Schemes
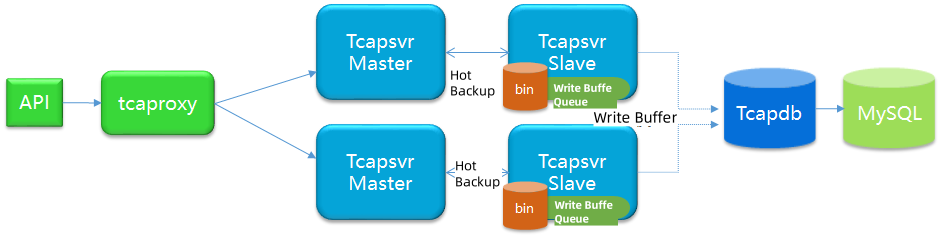
Table data buffering service means that Tcaplus incremental data can be buffered to third-party systems (currently supporting MySQL and Kafka) for product data query and analysis. The principle is that Tcapsvr synchronizes incremental write data (starting from enabling buffer) (based on Tcaplus Binlog) to Tcapdb, and Tcapdb writes/changes to MySQL or Kafka. Therefore, this function must ensure that the Tcapdb machine has access to MySQL or Kafka. If it is MySQL, it also needs to have permission to create tables in MySQL, otherwise the function cannot be successfully configured. The difference between MySQL and Kafka and applicable cases:
- Only one of MySQL and Kafka can be configured for one table. MySQL or Kafka addresses need to be provided by the app, and it needs to be ensured that Tcaplus has relevant access rights.
- MySQL buffering is suitable for apps that want to get relatively real-time data from a specified table (either all or part fields). When the buffer time window N is configured, Tcaplus merges the write requests in the last N seconds. The same records retain the last updated data and send it to Tcapdb ->MySQL. For MySQL, the default time window N is 30s. It can also be larger or smaller, depending on the real-time requirements of the app. It can be set 0, but it will not be merged. This is not conducive to performance optimization.
- Kafka buffering is applicable to the change action that the app wants to subscribe to the specified table (either all fields or part fields). Tcaplus sends the data before and after the change to Tcapdb ->Kafka. The time window is N, which defaults to 0 s for Kafka.
- Apps that use MySQL buffering can essentially accept the minute-level delay, so MySQL buffering is done on Slave by default, with little impact on online services,But when configuring MySQL buffering, you can set the 'buffering period' to 0, indicating that you do not want to delay. Apps that choose to use Kafka buffering generally require high real-time performance. Kafka buffering is done on the Master by default, which will consume some of the master's processing power.
Special note:
- The Tcaplus write buffering function only synchronizes the incremental data after enabling write buffering and modifies it to a third-party system. Data is not synchronized before buffering is enabled. If this part of data also needs to be synchronized, it requires the DBA to pull the cold backup, dump the Tcaplus engine file and import it to the third-party system, and then enable buffering.
- At present, the bottleneck of the whole buffering process lies in the CPU of the Tcapsvr synchronous thread. The maximum QPS of the single machine buffering on the Tcapsvr side can reach 8 w/s. The capabilities on the Tcapdb side can be expanded horizontally without bottlenecks.
Among them:
- Write buffer cycle: refers to the "buffer time window N" mentioned above, which represents the delay that data users can accept when synchronizing data from Tcapdb to a third-party system. The higher this value is, the less sensitive the user is to the delay. The Tcapdb side will de-duplicate the requests in the time window of the write buffer cycle (for example, there are multiple Replace operations for the records of the same key within 30 s. After de-duplication, it only needs to synchronize the content after the last replace to the third-party system, and the first two times do not need to be synchronized, which can eliminate the previous two requests), thus reducing the overall synchronization QPS and improving performance.
- Key field mapping: the mapping from the key field in the Tcaplus table to the key field in the MySQL table or Kafka table. If there is no special requirement, it is better to keep the table fields of the two systems consistent to facilitate problem location. Key fields of binary type (i.e., arrays and secondary fields in tdr, bytes and repeated types in pb) are not supported for buffering. For MySQL buffering, all key fields must be selected. For Kafka write buffering, key fields can be selected in part and can be dynamically adjusted and modified after the configuration takes effect. If part fields are selected, Tcaplus will only synchronize modifications containing these fields to Kafka. It is recommended to select all key fields.
- Value field mapping: the mapping from the value field in the Tcaplus table to the value field in the MySQL table or Kafka table. If there is no special requirement, it is better to keep the table fields of the two systems consistent to facilitate problem location. If the value field is of binary type, it will be synchronized to MySQL or Kafka in binary. It requires users to deserialize the parsing. For MySQL bufferingand Kafka buffering, value fields can be selected in full or in part. If part fields are selected, Tcaplus will only synchronize modifications containing these fields to MySQL or Kafka. After the configuration takes effect, it can be dynamically adjusted and modified.
- The message types sent by Tcaplus to Kafka are as follows:
INSERT:
{
"timestamp":"xxxx",//Update the tcaplus record
"type": "insert",
"appid": "app1",
"zoneid": "zone1",
"table": "test_table",
"keyfields":"k1,k2,k3",
"NewRecord":{"k1":"key1","k2":"key2","k3":"key3",
"v2":"Tom","v4":"10"}
}
DELETE:
{
"timestamp":"xxxx",//Update the tcaplus record
"type": "delete",
"appid": "app1",
"zoneid": "zone1",
"table": "test_table",
"keyfields":"k1,k2,k3",
"OldRecord":{"k1":"key1","k2":"key2","k3":"key3",
"v2":"Tom","v4":"5"}
}
UPDATE:
{
"timestamp":"xxxx",//Update the tcaplus record
"type": "update",
"appid": "app1",
"zoneid": "zone1",
"table": "test_table",
"keyfields":"k1,k2,k3",
"OldRecord":{"k1":"key1","k2":"key2","k3":"key3",
"v2":"Tom","v4":"5"}
"NewRecord":{"k1":"key1","k2":"key2","k3":"key3",
"v2":"Tom","v4":"10"}
}